

|
I don't have time/effort to respond to all of this (just compare benchmark results--I don't know of any GPU app in HPC that is actually flops bound instead of bandwidth bound), but a few things:Paul MaudDib posted:There's also a ton of work devoted to getting around the memory size limitation. Multiple GPUs in a system can do DMAs to each other's memory, so you can get up to 48GB of GDDR5 memory per system with 4x K40s. In theory you could also do DMA to something like a PCI-e SSD, which might offer better latency (but lower bandwidth) than main system memory. also, peer to peer latency is ~identical to system memory latency, although I haven't measured that in a long time. quote:We actually do have tools that let you write large parallel sections easily - OpenMP and OpenACC frameworks for exploiting loop-level parallelism in particular. On a finer grain there's marking calls as tasks and then synchronizing, etc. quote:The problem is that tools are much less of an effective solution when there's big overhead to start/stop a co-processor. That's my problem with the OpenACC approach to GPUs - it doesn't make sense to copy it down to the processor, invoke and synchronize the kernel, and then copy it back up to parallelize a single loop, GPU programs really should be running mostly on the GPU rather than shuttling data back and forth all the time. It makes sense for intensive portions that are reasonably separate from the rest of the program, but a generic "send this part of the program to the GPU" isn't really going to be the best solution in a lot of cases. this is the interesting part of APUs or KNL; by skipping PCIe, the quantum required for a speedup should be a lot lower. once it gets low enough to the point that arbitrary function dispatch can be profitable even if the CPU can just wait for the results to come back, then that will be transformative. however, that's probably going to look more like AVX512 or AVX1024 than a dedicated GPU. also, OpenACC actually tries to keep memory on the GPU as much as possible and isn't doing a naive copy-to/copy-back every time. quote:Of course, all such tools do have the problem that their design goal is to make it easy to write/adapt generic code. Writing applications using architecture-specific features can make a pretty big impact in performance. One reasonable approach to this would be to let you compile in OpenCL or CUDA code directly - i.e. you should be able to call __device__ functions that can use the architecture-specific features, perhaps with multiple versions to target different architectures.
|
 #
?
Aug 28, 2014 03:56
#
?
Aug 28, 2014 03:56
|
|

|

|
| # ? Apr 26, 2024 19:55 |
|
|
Just turn the Intel thread into CPU Discussion and this one into GPU Discussion. We're halfway there already! But please continue, this discussion is neat
|
|
#
?
Aug 28, 2014 05:41
|
|

|
Anyone else feelin' pretty dumb after the last few posts? Heck, I'm almost ready to buy an AMD CPU.
|
|
#
?
Aug 28, 2014 05:53
|
|

|
Factory Factory posted:Anyone else feelin' pretty dumb after the last few posts? Heck, I'm almost ready to buy an AMD CPU. Definitely some stuff going over my head, but the cool thing is the words stay there and I can go find out what I don't know  This is basically my idea of an ideal CPU thread - get some serious hardware/software crap going on! This is basically my idea of an ideal CPU thread - get some serious hardware/software crap going on!I'm still thinking on the last few posts but I do intend to reply, dunno 'bout you man. I know you've got the knowledge.
|
|
#
?
Aug 28, 2014 06:13
|
|


|
Factory Factory posted:Anyone else feelin' pretty dumb after the last few posts? Heck, I'm almost ready to buy an AMD CPU. 1. it takes a lot of parallel work to fill up a GPU, and GPUs can't timeslice between processes or anything like that when one task isn't offering enough work to completely fill the GPU. this limitation generally doesn't apply to CPU apps, so the problem with porting becomes more about restructuring the rest of your app to get enough work in a single place at a time than porting some kernels. 2. when everything about your platform (GPU type, GPU count, whether GPUs are shared or exclusive, CPU count, PCIe perf, ...) isn't known a priori, writing an application that uses the right processor at the right time becomes really hard. it's partially a language issue and partially a runtime issue. language-wise, the CUDA execution model (later used by OpenCL and DirectCompute) exposes some extremely low-level hardware details and in fact requires users to specify things at that level in order to get good performance. these include exact details of the memory hierarchy, warp widths and warp-synchronous programming, how a kernel traverses over data, etc--the developer has to control all of this to get something that runs fast. since those details change from GPU generation to GPU generation, there's no one ideal GPU kernel. runtime wise, there's no way to figure out how busy a GPU is (other than "is anyone else potentially using this GPU at all"), so picking a particular GPU to use in a multi-GPU system is also really hard. couple that with GPU performance variance between different models or different vendors, and the question rapidly becomes "should I use a GPU at all right now or stick to the CPU." the reason why GPUs have been pretty successful in HPC thus far is because #2 doesn't really apply--if you're buying 10-40k GPUs, you generally buy the same kind of GPUs and write software for that machine. most of the software improvements in recent years have been focused on #1 (GPU work creation, improved support for concurrent kernels, multi-process support, even interaction with InfiniBand and other NICs), and the rest of the porting problem can get brute forced by investing in enough software engineers. meanwhile, #2 is as critical an issue in desktop and mobile as #1, and there's been very little work to solve that. OpenACC and Thrust come to mind to solve the language issue, but there's still very little research on good runtime schedulers that I'm aware of (the last big thing was StarPU, and that was what, four or five years ago?). over time, #2 will become more important for HPC as there's less of a CUDA monoculture, but I don't have any idea as to what direction that will take right now.
|
|
#
?
Aug 28, 2014 18:30
|
|
|
What I'm getting from your earlier post is that most multithreaded applications are written with some type of "task-based" parallelization (you said TBB). For those reading along, this basically means that when a work item is received, the processing work is broken into a series of discrete tasks which can be accomplished in parallel. These tasks can then spawn further tasks of their own. There is often a requirement that all child tasks be finished before processing is allowed to continue. This sets up a dependency tree of tasks. So you might have: Work Item: spawn A, B, wait until A and B are completed, launch C,D Task A: no children Task B: spawn D,E, wait until completion Task C: no children Task D: no children In contrast there's also loop based parallelism. In some types of work, you have some big for loop that iterates and processes data items. Loop based parallelism approaches this by spreading the loop iterations between threads, to turn a for loop into data parallelism. So if you have 4 threads and 8 work items, you might get Thread0: data0, data1 Thread1: data2, data3 Thread2: data4, data5 Thread3: data6, data7 OpenMP and OpenACC are frameworks that handle distributing the iterations between threads. Professor Science posted:it's pretty straightforward. based on hardware alone, GPUs offer a pretty good value proposition for HPC (lots of BW, lots of FLOPs), but they are hamstrung by two big software issues. GPUs are fundamentally data parallel processors, they operate by lining up a bunch of pieces of data and performing the same sequence of operations on multiple pieces of data at once (a "warp" of threads). Task-based parallelism is not a good approach to SIMD processors, because all threads in a warp must follow all code paths. If you have 4 different code paths for your different tasks, every thread in a warp has to execute all 4 code paths (4 threads will be launched in a warp, 31/32 threads in the warp will be disabled per code path). Or with dynamic parallelism, you need to invoke 4 more kernels (4 32-thread kernels will launch of which 31/32 will idle) and then synchronize. I think the number of programs that really, truly can only express a low degree of parallelism is pretty low, though. As an example, consider something like video compression - you need to base frame n from the encoding of the prior frame n-1, so in a naive approach you can only process one frame at a time. Even so there's ways to artificially boost that - for example, maybe you can generate some estimate of what the previous frame is going to be (assume that it was encoded perfectly and there's no artifacting, etc) and then propagate an "error frame" forward that represents the difference from your estimate. Or do a search for keyframes, which mark the beginning of independent sequences of the video, and then process the independent sequences in parallel. That's what a lot of the "rewriting algorithms" looks like - finding ways to expose greater degrees of parallelism, instead of just having a single thread that chugs through a serial algorithm. I think one strategy is to try and generate your own data parallelism as you go. Latency already sucks compared to CPUs, so just embrace it and let a runtime batch up data items/tasks and then process them in parallel when possible. In terms of implementation strategies, I think that would end up looking a lot like the Erlang runtime. You have something that looks like lightweight threads which a runtime or the scheduler batches and then dispatches when a sufficient number of data items are ready (or the processor is under-utilized enough that processing partial batches doesn't matter). "Lightweight threads on GPU" isn't really an insignificant task, but I don't think it's insurmountable either. GPUs are built to launch vastly more threads than the multiprocessors can actually handle at once, to cover latency. Until the data is ready, the threads block and other warps can execute, Only here the launch condition is "32 successful stores from other threads' shared memory" instead of the current "32 successful reads from global memory". That looks a lot like Erlang actors to me - threads sitting idle until they're needed. I don't think you can make idling threads work with the current scheduler, but it doesn't seem like too much of a stretch, and you could potentially get the same effect using dynamic parallelism and just launching new kernels instead of waking up sleeping threads. That has overhead too of course, but you're amortizing it across more than 1 data item per launch, and kernel launch overhead is much, much lower from the kernel (onboard the GPU) than from the CPU. And it should be pretty easy on APUs. Which is again why I think they're such an interesting tech - the overhead to invoke the GPU is really low and the CPU can wrangle things into batches that are worthwhile to apply SIMD processing to. Instead of "make this entire program work on GPU" you're now talking about a more manageable target of "wrangle up a workable degree of parallelism with the CPU and then use the SIMD cores". It'll never be worth doing over a half dozen lines of code, but it should be worth using on stuff that is intensive enough to be worth explicitly marking as a task for parallelization. quote:2. when everything about your platform (GPU type, GPU count, whether GPUs are shared or exclusive, CPU count, PCIe perf, ...) isn't known a priori, writing an application that uses the right processor at the right time becomes really hard. it's partially a language issue and partially a runtime issue. language-wise, the CUDA execution model (later used by OpenCL and DirectCompute) exposes some extremely low-level hardware details and in fact requires users to specify things at that level in order to get good performance. these include exact details of the memory hierarchy, warp widths and warp-synchronous programming, how a kernel traverses over data, etc--the developer has to control all of this to get something that runs fast. since those details change from GPU generation to GPU generation, there's no one ideal GPU kernel. runtime wise, there's no way to figure out how busy a GPU is (other than "is anyone else potentially using this GPU at all"), so picking a particular GPU to use in a multi-GPU system is also really hard. couple that with GPU performance variance between different models or different vendors, and the question rapidly becomes "should I use a GPU at all right now or stick to the CPU." Well some of this is real and other stuff isn't. I generally agree that CUDA and OpenCL expose a lot of low-level mechanics to the programmer, but you don't really need to hand-tune your program to every single device to get good performance. If you're writing low-level C code for your entire program, yeah, your life is going to suck, but the higher-productivity way here is to write your program in terms of template library calls and then let the library authors handle tuning the operations to the various architectures. That's Thrust, Cuda Unbound, CUDPP, and so on, which handle warp-, block-, and device-wide collective operations. All of those are designed to be drop-in solutions that will work on any architecture or block size. Like CPUs, not all portions of your program are really critical, and libraries often cover most of the critical parts fairly well. As for grid topology, you can write some math which does some rough occupancy calculations at runtime and get a reasonable guesstimate. Here's Thrust's implementation. A wild-rear end guess of 32/64/128/256 threads and enough blocks to saturate the processor usually doesn't produce awful results, and there's a profiler that'll give you real-world tuning on this. The only real hard rule is that you should use a round multiple of your warp size, if you launch a 63 thread block you're cruising for trouble. Powers of 2 are also useful for exponential reduction patterns. Not quite sure what you mean by "warp synchronization", if you mean thread-fences around shared memory operations, that's roughly equivalent to the trouble caused on CPUs by forgetting to wait for task completion. It's a thing you need to remember, but one you'll notice right away when your 2880-core processor spews obvious race conditions at you. That previous example uses them (__syncthreads()), they're pretty basic. Other stuff here is not real at all. Warp size has been 32 threads for every CUDA Compute Capability spec so far. Traversing the kernel's grid over data is pretty straightforward, and the fact that blocks can't communicate basically eliminates the possibility that you're doing something not straightforward. If threads need to communicate, they go in a block together. There is definitely an API that lets you get GPU utilization. quote:the reason why GPUs have been pretty successful in HPC thus far is because #2 doesn't really apply--if you're buying 10-40k GPUs, you generally buy the same kind of GPUs and write software for that machine. most of the software improvements in recent years have been focused on #1 (GPU work creation, improved support for concurrent kernels, multi-process support, even interaction with InfiniBand and other NICs), and the rest of the porting problem can get brute forced by investing in enough software engineers. meanwhile, #2 is as critical an issue in desktop and mobile as #1, and there's been very little work to solve that. OpenACC and Thrust come to mind to solve the language issue, but there's still very little research on good runtime schedulers that I'm aware of (the last big thing was StarPU, and that was what, four or five years ago?). over time, #2 will become more important for HPC as there's less of a CUDA monoculture, but I don't have any idea as to what direction that will take right now. Yeah GPUs are not a general purpose computer, yet. They're obviously headed in that direction though, given CPU/GPU SoCs, Dynamic Parallelism, APUs, and so on. (sorry AMD guys, my experience here is mostly NVIDIA/CUDA  I know there's an equivalent library to Thrust for OpenCL, it's called Bolt) I know there's an equivalent library to Thrust for OpenCL, it's called Bolt)
Paul MaudDib fucked around with this message at 02:09 on Aug 29, 2014 |
|
#
?
Aug 28, 2014 21:23
|
|

|
Professor Science posted:it's pretty straightforward. based on hardware alone, GPUs offer a pretty good value proposition for HPC (lots of BW, lots of FLOPs)... I love the discussion but only made it this far into your post before not understanding anything anymore.
|
|
#
?
Aug 29, 2014 00:13
|
|


|
I'd also like to throw my hat into the ring of "too many words, but basking in the exchange between professionals like the smarmy superficial gamer I am".
|
|
#
?
Aug 29, 2014 00:22
|
|

|
eggyolk posted:I love the discussion but only made it this far into your post before not understanding anything anymore. It's a question of cpu-bound programs and memory bound programs. GPUs have a shitload of memory bandwidth because of their GDDR5 memory. A K40 has 288 GB/s of bandwidth, compared to <30 GB/s for DDR3 RAM. Memory is accessed through "ports", GDDR5 is a special type which (pretends to) allow two processors to access the same port at once, and the bandwidth is obviously huge. On top of that there's a shitload of engineering to get more out of the bandwidth that's there - for example, threads in the same warp (32 threads) can combine accesses to sequential addresses into a single request which is broadcast to all of them, and so on. Because they were originally designed to process graphics, they also have various special features which are designed to help that. For example, most memory operates with what's called 1d locality - memory is a flat space divided into pages, meaning accesses near a previously requested address are likely cached and happen much faster. By various tricks, GPUs allow 2d and 3d locality, which helps cache data that is close in 2d/3d space even if that doesn't translate into a nearby 1d address, which helps some problems. And on top of that there's special access modes that can perform extra floating-point calculations (interpolation, etc) for "free". Memory access and some calculations are combined into a single operation which doesn't use core processor cycles, but does have some extra latency. This is all necessary because GPUs put out a ton of floating point calculations (FLOPs). An i7-4770k puts out around 32 GFLOPs per core (x4), a K40 puts out about 4,290 GFLOPs. It's not a trivial task to feed that much data to the processor, even with that much bandwidth. An implication of this is that GPUs can perform a lot more intensive programs - from what I remember Kepler is up around 64 floating point operations per float of memory access, versus ~8 for a Haswell. On the other hand that's also problematic - it's easy for bandwidth to be the limiting factor, and memory bandwidth hasn't kept up with processor power. There's also not that much per card, and the workarounds aren't great, you're down to ~3-6 GB/s accessing somewhere else. Another factor here is latency. It does take a while to service all the FP calculations, memory requests, and possible code paths 2880 cores can throw out, even with bandwidth and tricks. So instead of a CPU, where you usually have ~1-2 threads per core, GPU programs often operate on the premise of "fucktons of threads, most of which are blocked". At peak a K40 can keep track of up to about 31k resident threads even if it can only execute 2880 at a time. In most cases multiprocessor shared memory or register pressure will limit that number though. Most of the architecture and programming paradigm is designed around making that manageable, and you need enough independent data items to keep it busy, so it's not universally applicable. Often it gets used to accelerate specific parts of programs with most of it remaining on the CPU, which seems pretty obviously better addressed with an APU. Or more likely, a Xeon Phi, which is the same-ish thing in that role. Paul MaudDib fucked around with this message at 01:46 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 00:32
|
|
|
Paul MaudDib posted:What I'm getting from your earlier post is that most multithreaded applications are written with some type of "task-based" parallelization (you said TBB). quote:I think one strategy is to try and generate your own data parallelism as you go. Latency already sucks compared to CPUs, so just embrace it and let a runtime batch up data items/tasks and then process them in parallel when possible. In terms of implementation strategies, I think that would end up looking a lot like the Erlang runtime. You have something that looks like lightweight threads which a runtime or the scheduler batches and then dispatches when a sufficient number of data items are ready (or the processor is under-utilized enough that processing partial batches doesn't matter). quote:That has overhead too of course, but you're amortizing it across more data items per launch, and kernel launch overhead is much, much lower from the kernel (onboard the GPU) than from the CPU. quote:I generally agree that CUDA and OpenCL expose a lot of low-level mechanics to the programmer, but you don't really need to hand-tune your program to every single device to get good performance. If you're writing low-level C code for your entire program, yeah, your life is going to suck, but the higher-productivity way here is to write your program in terms of template library calls and then let the library authors handle tuning the operations to the various architectures. That's Thrust, Cuda Unbound, CUDPP, and so on, which handle warp-, block-, and device-wide collective operations. All of those are designed to be drop-in solutions that will work on any architecture or block size. Like CPUs, not all portions of your program are really critical, and libraries often cover most of the critical parts fairly well.  quote:As for grid topology, you can write some math which does some rough occupancy calculations at runtime and get a reasonable guesstimate. quote:Not quite sure what you mean by "warp synchronization", if you mean thread-fences around shared memory operations, that's roughly equivalent to the trouble caused on CPUs by forgetting to wait for task completion. It's a thing you need to remember, but one you'll notice right away when your 2880-core processor spews obvious race conditions at you. That previous example uses them (__syncthreads()), they're pretty basic. 1. it's good for warps to be out of phase with each other within a block, as that makes it more likely that your various execution units will be in use while memory loads/stores are happening. in other words, __syncthreads() eats performance. 2. if you know the warp size, you know that all of your operations will be completed at the same time, meaning there's no such thing as an intra-warp dependency across an instruction boundary. so a simple example of this is the same thing you'd use warp shuffle for: code:quote:Other stuff here is not real at all. Warp size has been 32 threads for every CUDA Compute Capability spec so far. Traversing the kernel's grid over data is pretty straightforward, and the fact that blocks can't communicate basically eliminates the possibility that you're doing something not straightforward. If threads need to communicate, they go in a block together. There is definitely an API that lets you get GPU utilization. (I've written a _lot_ of CUDA. also blocks can communicate, I'll leave that as an exercise to the reader) Professor Science fucked around with this message at 02:52 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 02:41
|
|
|
Professor Science posted:(I've written a _lot_ of CUDA. also blocks can communicate, I'll leave that as an exercise to the reader) Spinlocked infinite-loop kernels? I was under the impression that falls into "seriously undefined behavior". Professor Science posted:Let me blow your mind: for a single kernel launch, this is absolutely false. GDDR5 latency sucks a lot. Like a whole, whole lot. GPUs may have 5-6x the memory bandwidth of CPUs, but they do so by having ~15x the memory latency. Reading across PCIe after fiddling a register is better than running a scheduler on a GPU on GDDR5. (If you can batch N kernel launches together at the same time, then yeah, it'll perform better from the GPU.) For global memory, sure, which is why I specified "shared memory" On-multiprocessor memory has much lower latency. Dynamic parallelism should then avoid this, right? Is there huge latency to dispatch a kernel to another multiprocessor? I heard you can also play games with sharing local memory? It would probably be manageable/feasible to run a single runtime engine/task scheduler per device, at least, if there's such a need for tasks and sufficient memory capacity to run multiple nodes per machine. The function calls should be the same, just different parameters (memory coherency would be reduced). I guess that should go in at the hardware/firmware level. Paul MaudDib fucked around with this message at 03:34 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 02:55
|
|
|
Paul MaudDib posted:Spinlocked infinite-loop kernels? I was under the impression that falls into "seriously undefined behavior". quote:For global memory, sure, which is why I specified "shared memory" On-multiprocessor memory has much lower latency. Dynamic parallelism should then avoid this, right? Not sure what you mean by sharing local memory. edit: wait, do you mean launching out of the equivalent of __shared__? Professor Science fucked around with this message at 03:37 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 03:28
|
|
|
This is incredible, and the level of discourse I wish we could have on every subject, holy poo poo.
|
|
#
?
Aug 29, 2014 03:46
|
|
|
Professor Science posted:edit: wait, do you mean launching out of the equivalent of __shared__? quote:A child grid inherits from the parent grid certain attributes and limits, such as the L1 cache / shared memory configuration and stack size So - basically you have some program with an update loop, with high thread divergence - say you have like 4/32 threads per warp that need to process something (making 32/32 threads sit through long latency). Or some other task/request/query that sporadically or asynchronously occurs but takes some effort to process. First you do a prefix-sum+atomicAdd+write or something to write the parameters for each task found (for each multiprocessor) into shared memory, with return pointers, etc. Iterate one update loop for all nodes of the problem, or until you get enough tasks to be worth dispatching early, then process all the tasks. Then process the next update loop and so on. Assuming this task selection process is free, we've increased our active thread count during this intensive task from 4/32 to 32/32 threads per warp, which is a significant increase in processing power, and we're not making every data item sit through the latency for the 12% that are processed. If you launch a kernel from there to pick off the parameters and do the tasks, it shouldn't add much additional access latency over the update loop calling the function directly (just a couple round-trips from shared memory, which is quick), but it should decrease divergence because most of the threads are doing things (as opposed to being masked to disabled), right? Implement that with a lightweight threading system to process the tasks. Do warp scheduling that allows cross-block/cross-grid processing of reasonably large tasks based on function call scheduling, or instruction address, or something like that. That's basically the "task parallel" approach on GPU, you're not going to get single data items to process efficiently. Paul MaudDib fucked around with this message at 04:46 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 03:56
|
|
|
maybe I'm not following you, but either you can't assume that the same SM is going to run the new kernel (%smid in PTX is effectively volatile, after all) or you don't need dynamic parallelism. also you should get plat or some other easy means of contact.
|
|
#
?
Aug 29, 2014 04:14
|
|
|
One time I programmed a method for taking screenshots at high speed by installing FRAPS, setting up a small RAM drive, and having a while loop mash the screenshot hotkey. I am totally qualified to contribute meaningfully to this conversation.
|
|
#
?
Aug 29, 2014 04:26
|
|
|
Professor Science posted:maybe I'm not following you, but either you can't assume that the same SM is going to run the new kernel (%smid in PTX is effectively volatile, after all) or you don't need dynamic parallelism. Yeah I guess that's wrong, dynamic parallelism kernels can't be passed shared or local memory. You could do block-wide task processing without DP I guess. The ability of a kernel to be instantiated on a single SM probably would be really useful though. Like being able to lock a stream's processor affinity or something like that. That plus the ability for the hardware scheduler to block until incoming memory writes are completed (as opposed to outgoing memory requests) would basically be a lightweight task/threading system, which is what I've been going at. And again this is all way easier assuming you have a real CPU to handle data wrangling on, so APUs should be better at tasks. quote:also you should get plat or some other easy means of contact. AIM's good. In the profile. Or 
Paul MaudDib fucked around with this message at 04:49 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 04:30
|
|
|
Paul MaudDib posted:It's a question of cpu-bound programs and memory bound programs. This makes a lot more sense. Thank you. It's also makes me wonder why people speak about the shift from DDR3 to DDR4 as a relatively unimportant or inconsequential step. If memory bandwidth is such a limiting factor as you say, then while isn't there more development on the thinnest point of the bottleneck?
|
|
#
?
Aug 29, 2014 04:59
|
|
|
Professor Science posted:(I've written a _lot_ of CUDA. also blocks can communicate, I'll leave that as an exercise to the reader) Generally, you can communicate through global memory by writing/reading from shared regions of memory. One major difficulty is that you can't guarantee that two workgroups that you expect to communicate will ever be scheduled at the same time (so spin locks are likely to deadlock the kernel). Another is that the caches used by the workgroups are not guaranteed to be coherent (meaning a spin lock may never see the updated variable, again deadlocking the kernel). The first problem may happen because your workgroups may legally be scheduled in any order the hardware pleases. As such, if you expect workgroup 2 to receive a value from workgorup 1: workgroup 2 may start spinning waiting for the value, but workgroup 1 can't be scheduled because workgroup 2 is in the way. You can fix the first problem by carefully assigning a custom workgroup ordering ID based on the order that workgroups that are scheduled try to access some global structure -- an ugly hack, but it works. The latter problem happens because the write from the first thread may go out to DRAM, but the spinning thread may have the old value in its L1. It keeps hammering on that value, so it's never evicted. It never sees the updated value from DRAM and continues on for eternity. The source code for the second paper has this problem. It works on modern Nvidia GPUs and older AMD GPUs, but deadlocks on AMD GCN parts. You can replace both the write and the spin-read with atomics, which should push those writes and reads out to the coherence point (the shared L2 in AMD GPUs). You'll also need to be careful with atomicity here, because atomic operations are not ordering fences in a workgroup -- you would need to put explicit global memory barrier in place to make sure all of the threads in a workgroup are done with these atomic writes before you move on. Adding required coherence in the HSA specification and OpenCL 2.0 will help this mess. (A good presentation on this.)
|
|
#
?
Aug 29, 2014 05:11
|
|
 Failed Sega Accessory Ahoy!
Failed Sega Accessory Ahoy!
|
Menacer posted:You can replace both the write and the spin-read with atomics, which should push those writes and reads out to the coherence point (the shared L2 in AMD GPUs). You'll also need to be careful with atomicity here, because atomic operations are not ordering fences in a workgroup -- you would need to put explicit global memory barrier in place to make sure all of the threads in a workgroup are done with these atomic writes before you move on. It's worth noting that atomics completely bypass the caching system in CUDA (obv not AMD). They are explicitly operations that are guaranteed happen to their target memory before the call unblocks. With all the costs and/or implied failure that that entails. Paul MaudDib fucked around with this message at 05:32 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 05:22
|
|
|
eggyolk posted:This makes a lot more sense. Thank you. It's also makes me wonder why people speak about the shift from DDR3 to DDR4 as a relatively unimportant or inconsequential step. If memory bandwidth is such a limiting factor as you say, then while isn't there more development on the thinnest point of the bottleneck? John McCalpin has an excellent series of blog posts detailing how difficult it can be to tweak a CPU application to use as much bandwidth as possible: 1, 2, 3, 4. An image summing up the work it takes to squeeze bandwidth out of a single thread: 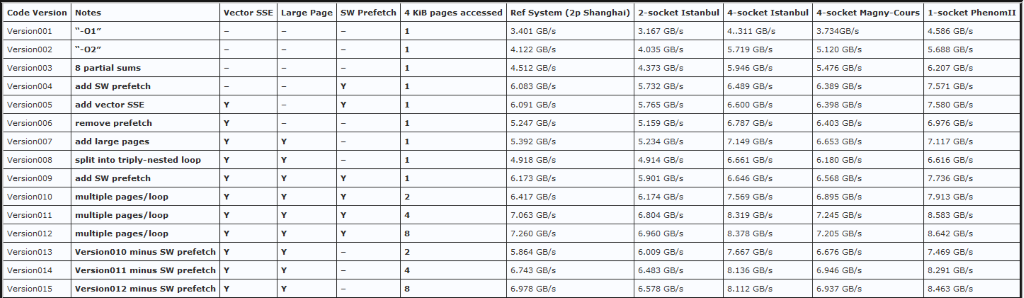 A core's ability to effectively use more bandwidth also depends on a lot of microarchitectural factors. This means it can take new processor generations before some bandwidth thresholds can be crossed. If you can write a program that uses multiple cores, it's easier to push up against bandwidth limits. However, core counts aren't skyrocketing in consumer parts, and many programs are still weakly parallel. This all combines to mean that, while DDR4 is important and necessary in some fields, you likely won't see profound performance improvements in your day-to-day applications.
|
|
#
?
Aug 29, 2014 05:37
|
|
|
eggyolk posted:This makes a lot more sense. Thank you. It's also makes me wonder why people speak about the shift from DDR3 to DDR4 as a relatively unimportant or inconsequential step. If memory bandwidth is such a limiting factor as you say, then while isn't there more development on the thinnest point of the bottleneck? I finally have something useful to add: There has been quite a bit of development! But rather than improving the DRAM bus, it's been more in the direction of using predictive prefetch and lots of cache, so that a significant percentage of accesses out to DRAM are in progress or finished by the time they are needed. These techniques and the underlying hardware, which are iterated on with each uarch generation, are combined with multiple levels of cache. Cache memory is closer to the chip than DRAM and so can be accessed with less latency and higher bandwidth, with the trade-off that the closer you get, the less room there is for large amounts of memory. It's pretty much standard these days for the cache levels to be coherent. Nutshell: if one core is operating on an area of memory, another core will be able to see those changes in real time. This description is probably an oversimplifcation, so have a giant Wiki article I guess. For example of progress in cache, here's a table I ganked from AnandTech about the iterations on cache size, latency, and bandwidth across three Intel uarchs:  These are only per-core numbers. L3 cache is shared among the cores and the entire chip. For a fully decked-out quad-core die, there are 64 KB of L1 cache per core, 2 MB of L2 per core, up to 8 MB of L3 chipwide, and an optional 128 MB L4 (Crystalwell). Most CPUs and APUs above the netbook/nettop level have three levels of cache before the memory controller ever has to be involved. Three-level cache was a supercomputing feature in 1995. In 2003, on-chip L3 cache was an esoteric server feature on Intel's Itanium (as well as optional off-chip L4). In 2008, AMD's Phenom II made L3 cache a high-end desktop feature. Now it's pretty much a given in a notebook or larger CPU, and it's becoming more common in ultra-mobile parts (especially ones with high-performance GPUs). Some desktop/notebook Intel chips using integrated graphics implement an L4 cache, Crystalwell - an off-chip SRAM cache that's only 128 MB, but it runs super fast (compared to DRAM) and is something like half the latency of going all the way out to DRAM. In server chips, right this instant it's mostly just enormous L3 cache. The Next Big Thing in avoiding RAM access is using stacked DRAM technology to put a shitload of memory right next to the CPU on the same package, used as last-level cache. Nvidia has it on the roadmap a few GPU uarchs down, Intel is already doing it with their current-gen many-core Knight's Whatsit (up to 16 GB of L4 cache for like 70 Silvermont Atom cores). So it is getting worked on! But rather than simply making the bottleneck wider, development is going into avoiding reaching a bottleneck state in the first place. Factory Factory fucked around with this message at 06:40 on Aug 29, 2014 |
|
#
?
Aug 29, 2014 06:21
|
|
|
Factory Factory posted:Nvidia has it on the roadmap a few GPU uarchs down, Intel is already doing it with their current-gen many-core Knight's Whatsit (up to 16 GB of L4 cache for like 70 Silvermont Atom cores). In the spirit of this thread's ostensible subject, it's likely that AMD is working on this too. They haven't announced any products, though. Knight's Landing will have mode bits to decide how the interposed DRAM will be used. You can choose between using it as a very large hardware-controlled cache, a software-controlled scratchpad, or a combination. This is likely because different applications in the HPC community reuse data in different ways, and software control over what values are "close" can result in much better performance for some important apps they're targeting. Many applications don't want to think about memory at all, however, and would like to default to hardware-managed caching.
|
|
#
?
Aug 29, 2014 06:43
|
|
|
In response to last page posts calling for new threads, I think it would be appropriate to create 4 AMD threads, each with 2 topics being discussed within.
|
|
#
?
Aug 29, 2014 15:17
|
|

|
Bloody Antlers posted:In response to last page posts calling for new threads, I think it would be appropriate to create 4 AMD threads, each with 2 topics being discussed within. Restrict each thread to say 3 posts per day as well.
|
|
#
?
Aug 29, 2014 15:39
|
|

|
Right AMD, put your only worthwhile Radeon brand you and slap it onto SSDs made by the most notorious PC-associated brand (OCZ) you can find. Did someone in AMD went mad or something?
|
|
#
?
Aug 30, 2014 17:19
|
|

|
Palladium posted:Right AMD, put your only worthwhile Radeon brand you and slap it onto SSDs made by the most notorious PC-associated brand (OCZ) you can find. Did someone in AMD went mad or something? I think OCZ actually has positive brand recognition among most people who buy aftermarket SSDs. The power of good marketing!
|
|
#
?
Aug 30, 2014 23:09
|
|

|
Which is hilarious considering the failure rate of SandForce based controllers.
|
|
#
?
Aug 31, 2014 00:30
|
|



|
orange juche posted:Which is hilarious considering the failure rate of SandForce based controllers.
|
|
#
?
Aug 31, 2014 01:28
|
|

|
 New CPUs, same 8 cores and clock speed but now at 95W TDP
|
|
#
?
Sep 2, 2014 17:44
|
|

|
calusari posted:
Looks like they're competitive with i5's in certain media creation benchmarks. And not much else.
|
|
#
?
Sep 2, 2014 20:07
|
|

|
This is probably the wrong thread, but I'm not sure that there is a right thread for this question, and the conversation recently has become highly technical, so I'm hoping some eyeballs here can answer this question. How much do we know about the 64b Denver SoC? From a high level, does it sound a little bit like what intel does with x86 on their CPU's, [x86 being CISC, but internally the instructions are broken down into smaller bits and micro-ops]. ARM's ISA is already RISC so I'm not sure that the two ideas are comparable, but I'm just looking for someone to explain in a way I can understand what exactly nvidia thinks it's gaining by doing this transmetaish implementation of the ARM v8 ISA. My best guess from reading about the Denver 64b SoC is that they are moving to an in order execution pipeline and that they are saving more power that way (over OoO) than they are spending on the extra translation step done internally, and that this results in overall better perf/watt. But that just seems impossible to me, like cold fusion.
|
|
#
?
Sep 3, 2014 22:35
|
|

|
I've got what feels like an ancient Phenom II 840 on an AM3+ board that was purchased before Bulldozer. I'm looking at upgrading just the processor to help stretch out the life of the computer. Would an FX-8350 give me anything extra or would I be wasting money? My only alternative is an 8320 or a 9590 (and I am not buying that one). If there isn't any benefit I am just going keep going with this until whatever comes out after the 14nm process from Intel.
|
|
#
?
Sep 4, 2014 10:47
|
|
|
Lord Windy posted:I've got what feels like an ancient Phenom II 840 What do you run on your computer? Right now the most rational answer is to drop your AM3+ mobo like a rock and get a Pentium G3258 CPU+board combo from Micro Center and overclock the daylights out of it. Immediate boost to most things most people do, plus it won't even cost as much as an octo-"core" FX-anything.
|
|
#
?
Sep 4, 2014 10:57
|
|
|
Sidesaddle Cavalry posted:What do you run on your computer? Right now the most rational answer is to drop your AM3+ mobo like a rock and get a Pentium G3258 CPU+board combo from Micro Center and overclock the daylights out of it. Immediate boost to most things most people do, plus it won't even cost as much as an octo-"core" FX-anything. I mostly just play games on it. I have a 560ti Video Card, 16GB of RAM and a 7200RPM HDD. I know a Solid State Drive would get me better performance, but my issue is more that CK2 and co are starting to get slower and I think that is more a CPU thing than SSD. I live in Australia so I don't have a Micro Centre. I can get a G3258 for $78 and the cheapest Haswell Refresh Board is an Asrock H97M for $101. Though Umart is a clusterfuck and I don't know what the hell their motherboard section means. http://www.umart.com.au/umart1/pro/index.phtml?bid=2 http://www.msy.com.au/Parts/PARTS.pdf These two are the companies I would be buying from. EDIT: I have a 'you-beaut' laptop that is faster than my Gaming PC, but it's a Mac and the video card is poo poo. I mostly just remote in to my main PC to play those games so the laptop doesn't run at 90 degrees. I mostly use it to program and stuff. Lord Windy fucked around with this message at 13:05 on Sep 4, 2014 |
|
#
?
Sep 4, 2014 13:03
|
|
|
Lord Windy posted:I've got what feels like an ancient Phenom II 840 on an AM3+ board that was purchased before Bulldozer. I'm looking at upgrading just the processor to help stretch out the life of the computer. buying another AMD processor would be a waste of money. As has been mentioned you can grab that $70 overclocking pentium, and a cheap z97 mobo and blow the socks off any AMD CPU out there, at least in gaming and other not hugely threaded workloads. Note that you'd need a z97 mobo, not H97. This is your cheapest option: http://www.umart.com.au/umart1/pro/Products-details.phtml?id=10&id2=376&bid=2&sid=197452 (good god umart needs to fire whoever designed their website) Also note that the value in that Pentium relies on being able to overclock the poo poo out of it; if you aren't willing to overclock you should get an H97 board instead and a core i3. You really should also try to get an SSD at some point. The Lord Bude fucked around with this message at 13:12 on Sep 4, 2014 |
|
#
?
Sep 4, 2014 13:06
|
|
|
Please follow the poster above, he is saying what I want to say but better and more relevant to you
|
|
#
?
Sep 4, 2014 13:22
|
|
|
The Lord Bude posted:buying another AMD processor would be a waste of money. As has been mentioned you can grab that $70 overclocking pentium, and a cheap z97 mobo and blow the socks off any AMD CPU out there, at least in gaming and other not hugely threaded workloads. Haven't a lot, if not all the major motherboard manufacturers released BIOS updates recently that allowed overclocking on the cheaper platforms? I see a lot of combo deals on like Newegg that pair a Pentium Anniversary Edition with an H81 motherboard for example and the reviews indicate that overclocking works fine with that Pentium. My understanding is support is limited to Haswell Refresh and the Pentium in these situations, but you can save even more money without having to buy a Z97 mobo. I usually see the Pentium + mobo paired for 75-80 dollars.
|
|
#
?
Sep 4, 2014 13:29
|
|

|
Civil posted:Looks like they're competitive with i5's in certain media creation benchmarks. And not much else.  I secretly enjoy seeing the Phenom X6 post higher numbers than any other AMD CPU in the last 4 years.
|
|
#
?
Sep 4, 2014 13:37
|
|

|

|
| # ? Apr 26, 2024 19:55 |
|
|
I was about to ask "how do you know this will be better" but even in just GHz, the mobo Bude suggested beats the poo poo out of practically everything AMD offers. Last question, where do I go to learn more about overclocking? Edit: I know Ghz != speed, but I think I am safe in thinking that Intel Ghz > AMD Ghz
|
|
#
?
Sep 4, 2014 13:46
|
|