

|
Clojure is pretty drat cool. I'm learning it for the express purpose of wrapping my head around functional programming in general. I wanted to go through Functional Programming in Scala, but I felt like I didn't have the FP background for it. What are some good language-agnostic resources for the basics and theory behind FP?
|
 #
¿
Apr 30, 2015 16:21
#
¿
Apr 30, 2015 16:21
|
|




|

|
| # ¿ Apr 28, 2024 07:52 |
|
|
I've been meaning to get into Racket and Elixir more, too. Clojure's taking up most of my side-time, though. I'm considering making a basic lovely web app using Leiningen and Luminus, just to get used to the language. (It helps that Clojure can use Java packages.) Elixir's next on my list.
|
|
#
¿
May 2, 2015 00:29
|
|
|
I'll mo your nad.
|
|
#
¿
May 4, 2015 14:54
|
|
|
Hass-kull.
|
|
#
¿
Jun 13, 2015 18:57
|
|
|
What is functional programming poor at or incapable of, really? You can't do classes and procedural stuff, but that's kind of by definition.
|
|
#
¿
Jul 21, 2015 15:00
|
|
|
What sort of techniques are good for handling data structures in FP? I've already noticed that things like recursion and tail-call optimization needs you to pass in something like an accumulator, your previous value, and you current value, but it's never quite sunk in.
|
|
#
¿
Aug 3, 2015 15:03
|
|
|
Might as well do it in a config file or something.
|
|
#
¿
Sep 17, 2015 18:28
|
|
|
The Lisp thread got archived or something, so I'm gonna guess that this is where we ask Clojure questions. I've been trying to implement the card game War in Clojure. It's very simple: technically, there's two players, but there are basically no decisions made by either player so it can be programmed as a zero-player game. This boils the game down to an initial state, and a certain pipeline it goes through for each "tick" of the game. That means you can play the game by just pushing the state through the pipeline over and over, and rendering it to the screen when it comes out of the pipe. I understand the logic of the game, and know what steps need to be taken, but the code I wrote for it is goddamn awful: Lisp code:How can I improve this code, and the project in general? How would someone who's better at programming in Lisp than I am approach a problem like this? Does what I'm doing make sense, or is it in need of serious refactoring?
|
|
#
¿
Feb 18, 2016 20:07
|
|
|
I think part of the problem is that I'm constantly associng things into game-state as the return value for every function. I feel like if I have to do that so often, I might be doing it wrong. Functional data structures are kind of a pain to work with in my experience since you constantly have to haul around a reference to the top-level data structure and assoc new attributes into it, which can reach several layers deep. But maybe that's just because of how I approached the problem 
|
|
#
¿
Feb 18, 2016 23:26
|
|
|
Okay, I'm having trouble writing idiomatic Clojure code in terms of architecture and top-down vs. bottom-up programming. I'm scaling way the gently caress back and just making a plain library that plays War. The idea is that there is one data structure: the game. Lisp code:The hard part is coming up with the functions. I want to just do something like this to advance the game state one tick: Lisp code:Lisp code:Lisp code:Lisp code:You can tell that I'm not terribly satisfied with the results. Sure, it theoretically works, but I'm not sure how to test and debug it. lein repl doesn't seem to have any step-debugging or breakpoints, so I have to rely on println, which sucks butt. And in terms of application architecture, this ended up being top-down as opposed to bottom-up, because that's just how I'm used to doing things. It's a lot more straightforward to go from a full representation of the game as opposed to individually defining cards, then decks, then players, then the game. I'm also realizing that most of these functions should be marked private, outside of tick-game. Plus, some of them are just plain awful. award-winnings and resolve-match are particularly ugly, and I don't feel like I understand Clojure (or Lisp in general) well enough to write these functions right the first time. What am I missing here? Did I take a sensible approach to developing this program? What should my workflow be? What do I need to learn to be good at this language, and make things that are better than just endlessly nested functions on a data structure or two? I see people putting together loving, like, graphs and nodes and channels and systems everywhere, and I have no idea how I'd do that in Ruby, let alone Clojure. 
|
|
#
¿
Mar 11, 2016 19:09
|
|
|
Anything that isn't CLR or game development targets Linux and OSX over Windows.
|
|
#
¿
Mar 16, 2016 12:05
|
|
|
Larger and more active development is occurring on Linux platforms for tech focused on it, which means that not only is the ecosystem more mature, it's also more likely to be up-to-date and easy to use. Popular use trumps platform.
|
|
#
¿
Mar 16, 2016 13:27
|
|
|
+1 for VMs. Not having to worry about dealing with differing environments and being free to use whatever editor/IDE you want is really beneficial.
|
|
#
¿
Mar 17, 2016 11:42
|
|
|
tekz posted:I guess I'll start with Elixir; http://elixir-lang.org/learning.html has a few options. I'm thinking of picking up the O'Reilly book, but if anyone has another recommendation please let me know. Programming Elixir has been pretty great so far. Most Pragprog books are good, in fact.
|
|
#
¿
May 4, 2016 23:16
|
|
|
So I hear a lot about Lisp's extensibility and metaprogramming capabilities, and how it's good for defining a problem in a language that maps directly to said problem domain. People talk about domain-specific languages and macros and bottom-up programming and "changing the language to suit the problem" which makes it seem a lot more like dark-arts wizardry than a programming language. I don't really understand what this all means, and how it makes Lisp so powerful/versatile. I get the concept of domain specific languages, even if I have no idea how to make one or what makes a good DSL good, and I understand that homoiconicity means that everything is just data, including code. But I can't seem to connect those concepts to understanding and writing code that maps directly from problem domain to implementation. It feels like there's supposed to be an aha-moment with Lisp that I haven't had yet, and I don't know what I'm missing. What am I looking for, and how do Lisp's killer features matter in programming it well?
|
|
#
¿
May 18, 2016 23:39
|
|
|
I think the "personal project that fits" part is what trips people up. It's hard to map the usefulness of code-as-data-as-code and macros if your typical use case is setting up a web application or making an app with a GUI.tazjin posted:For me the lisp aha-moment happened when I started using structural editing for it (paredit in emacs), that's when I realised how the syntax and everything is just superficial and that data is code and how the universe really works. I got that first part, where everything's the same under the hood, but apart from that I'm a little lost. I read the article, and I think I'm starting to get it. The XML and to-do list example is a good starting point, but it feels like that's just one particular application of it, and I'm not sure how to apply it to anything else. I can see flashes of brilliance there when you realize that the entire point is about transforming data in a functional manner, but that kind of loses its luster when you work in FP-ready languages already. The one problem I have with macros vs. functions is that everything you can do with macros, you can do with functions. At least, as far as I can tell. As someone who mostly uses FP, I reach for a data-transforming function over a macro since that's what I'm used to. I don't feel the need to use macros, almost ever, so I don't really have a reason to understand them. What could help is to have some sort of exercise where you give people some plain s-expressions meant to represent some kind of data structure, and have people write something that makes that chunk of data into a program. I think that's the crux of the matter - the fact that programs are data in Lisp confuses people, because everyone considers programs and data to be wholly separate things in their minds. Programs do things, whereas data are things. One becoming the other never happens, perceptually, and maybe that's the problem. "Code is data" is readily understood, but "data is code" might just be the missing piece. Here, this is something awful: Lisp code:1. Using only functions, and 2. Using only macros. Forums, boards, threads, posts, and users all have different pretty-print formats. For example, I want all forums to be displayed in UPPERCASE LETTERS, all users to be printed like Pollyanna says:\n, all posts to be printed like this: code:Pollyanna fucked around with this message at 16:24 on May 19, 2016 |
|
#
¿
May 19, 2016 16:21
|
|
|
 I dunno, then. This is just kind of my impression of what that article was trying to teach me, and what the whole magic/zen enlightenment of Lisp is. I just wanna know how to make things really bullshit easy and dead simple, and macros seem like a good way to do that. How, I don't know, but it's what people seem to be saying about them. I dunno, then. This is just kind of my impression of what that article was trying to teach me, and what the whole magic/zen enlightenment of Lisp is. I just wanna know how to make things really bullshit easy and dead simple, and macros seem like a good way to do that. How, I don't know, but it's what people seem to be saying about them.Siguy posted:I was talking a little out of my rear end since I didn't put much effort into learning Common Lisp, but all the built-in functions felt very old-school and weird to me, with lots of abbreviations and terminology I wasn't familiar with. That doesn't mean they're bad necessarily and I probably overstated saying they have no logic, but as someone new to the language I didn't understand why sometimes a common function would be a clear written out word like "concatenate" and other times a function would just be "elt" or "rplaca". This is basically not a thing in Clojure, which is the newest dialect running on the JVM. Check it out: https://www.conj.io/
|
|
#
¿
May 20, 2016 04:15
|
|
|
I'm doing some Elixir practice projects and the concept of OTP and functions as processes is definitely interesting, but I'm having a hard time understanding the real world application of it and why you would want to structure a system that way, and what kind of common problems/notable systems and products call for OTP. What is it usually used for? Phoenix always talks about chat apps 'n stuff, but that seems like a different thing to me.
|
|
#
¿
Jan 4, 2017 16:22
|
|
|
MononcQc posted:Rather than making a very long post about this from scratch, I'll source a transcript of a talk I gave on 'The Zen of Erlang' that mentions what OTP can bring to system structure: http://ferd.ca/the-zen-of-erlang.html ...Huh. That's actually pretty loving cool. I've never really thought of programming that way. Web apps, where I've spent 99% of my dev time, don't usually match up to this kind of approach - at least, not the ones I've ever worked on. I feel kinda left out now. It seems like all the interesting software stuff is kept away in places where Rails monkeys like me don't really get the chance to work on them and learn from it. I want to get more involved in cool stuff like this, so I've been making moves towards branching out and  ing my way into one of these kinds of projects. Teams are moving towards more functional and alternative coding styles now, so I hope my skills end up in demand. ing my way into one of these kinds of projects. Teams are moving towards more functional and alternative coding styles now, so I hope my skills end up in demand.
|
|
#
¿
Jan 15, 2017 21:52
|
|
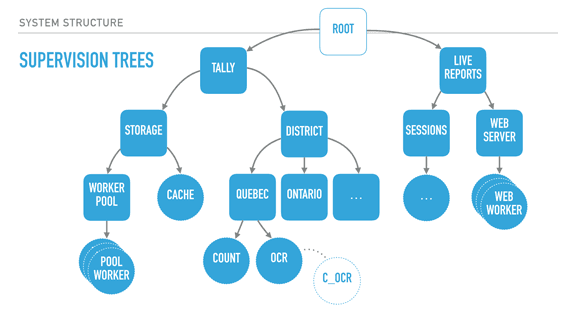
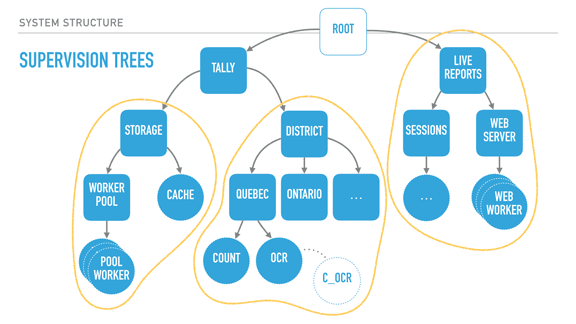
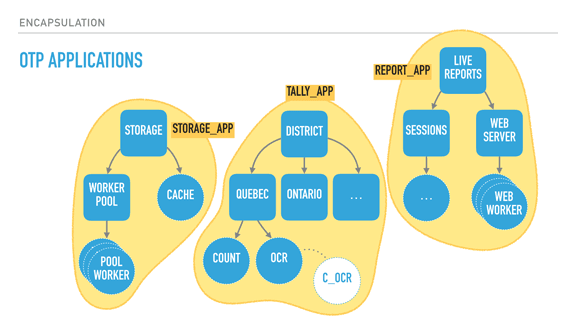
|
So the common idea of "HTTP is stateless and you must assume the connection and requests are too" still holds, but individual connections are considered their own processes? What advantage does this have over the previous one-process model? I can see the obvious picks of parallelization, but there's also concerns like database access that could limit the benefits from that...I'm not a web dev genius, just a monkey, so maybe I'm missing something. As a general system architecture, too, I can see how it'd be useful, but I still need some practice and experience to really grok it.
|
|
#
¿
Jan 17, 2017 16:11
|
|
|
I can understand why you'd want to write your systems and applications as a process tree, but I haven't yet developed a sense of what use cases those would be. I guess I haven't had a need to work on uptime critical systems before, but it sure sounds interesting. I got pretty far into LYAH, so maybe LYSE is up next. Edit: I have to say, Elixir/Erlang, OTP and the BEAM are how I expected computer programs to work in the first place, so it's nice to see that I wasn't totally off. xtal posted:Self-quoting for context. How much of a coding horror would it be for me to make a Lisp syntax for Rust using Haskell and parsec? As long as it isn't a security critical thing, 
Pollyanna fucked around with this message at 15:46 on Jan 18, 2017 |
|
#
¿
Jan 18, 2017 15:43
|
|
|
xtal posted:What implications would that have for security? Do you mean it's just silly to make our own language? I mean that anything goes really. Ignore what I said about security, I don't know anything about it.
|
|
#
¿
Jan 18, 2017 18:34
|
|
|
I don't see Elixir lasting very long without OTP also becoming a valued asset. It's a functional Ruby otherwise and it would need more of an edge than that to survive long-term. It helps that OTP is relatively simple in concept, at least.
|
|
#
¿
Jan 19, 2017 14:18
|
|
|
I just kinda assume that any of the magical stuff that Lisp does was subsumed into modern languages long ago, so none of it is impressive or out of the ordinary for those of us using anything newer than COBOL.
|
|
#
¿
May 6, 2017 21:56
|
|
|
I will admit that I have trouble understanding the advantage of having direct access to the AST of a function.
|
|
#
¿
May 7, 2017 22:39
|
|
|
Shinku ABOOKEN posted:can someone motivate me to learn clojure? what can it do better? a demonstration would be nice. The value I found in Clojure is 1. it looks cool and Lisp is cool 2. I wanted to get better at it. Other than that, you can pretty much say for 99% of everything "why would I want to do this when I can already do it with X?", so I can't really help you there cause I'm very similar to you in that regard Trying to psyche myself up to try making Doom WADs in a very similar fashion, actually.
|
|
#
¿
Aug 30, 2017 10:15
|
|
|
strange posted:I asked this in the general questions thread and was recommended to ask here: Side project web dev, specifically? Clojure by far. Clojure has a pretty robust selection of web development libraries ranging from basic HTTP handling, to SQL abstraction, to API management, and there's at least one legit web dev book to learn from. Disclaimer: I am basically the opposite of a greybeard, so take my advice with a grain of salt. But, I have had good experiences doing web dev in Clojure!
|
|
#
¿
Sep 28, 2017 13:30
|
|
|
My one gripe with Clojure is the lack of an ORM, which is entirely because my SQL skills are relatively lacking. 
|
|
#
¿
Oct 1, 2017 15:38
|
|
|
True. Datomic is a better fit overall for Clojure, I just don't have a whole lot of familiarity with it. It makes sense to lean on it first, though.
|
|
#
¿
Oct 1, 2017 21:14
|
|
|

|
| # ¿ Apr 28, 2024 07:52 |
|
|
xtal posted:The best ORM is no ORM Fair enough, and I do remember this sort of SQL templating happening when I made stuff with Luminus.
|
|
#
¿
Oct 2, 2017 00:13
|
|